Fixing VAE model reconstructions - training with different loss function: why and why it works
In my journey to deepen my understanding of machine learning, I decided to implement various models from scratch, starting with Autoencoders (AEs) and gradually progressing to more complex architectures like Variational Autoencoders (VAEs). Each step has been a valuable learning experience, helping me grasp the theoretical concepts while gaining hands-on expertise. However, when I started working on the VAE, I ran into unexpected challenges that threw off my initial results.
At first, I couldn’t pinpoint the issue-everything seemed to be in place, yet the model’s reconstructions outputs were far from what I had expected. This post will walk through the problem I encountered, the steps I took to investigate it, and ultimately how adjusting a key component-the loss function-led to a breakthrough.
For this experiment, I trained my VAE on the MNIST dataset-a collection of handwritten digits that’s widely used for benchmarking machine learning models. The objective of the VAE was straightforward: to encode each image into a compact latent vector and then decode that latent representation back into an image. Ideally, the reconstructed images should closely resemble the originals, demonstrating that the model has effectively learned a meaningful representation of the data in the latent space.
This process not only tests the VAE’s ability to compress and reconstruct data but also highlights its generative capabilities-allowing the model to sample new images by decoding random latent vectors. However, despite a seemingly correct implementation, my initial results didn’t align with these expectations.
The problem: Identical, Blurred Reconstructions and a Sudden Loss Drop
As I trained the VAE, a strange behavior emerged: no matter which 16 different digit images I fed to the model, the decoder consistently produced the same reconstructed images, it was nearly identical across all inputs. The reconstructed image was highly blurred, with most of the pixel intensity concentrated in the center. Clearly, this was not the expected outcome, we would expect at least some variations in the reconstructions.
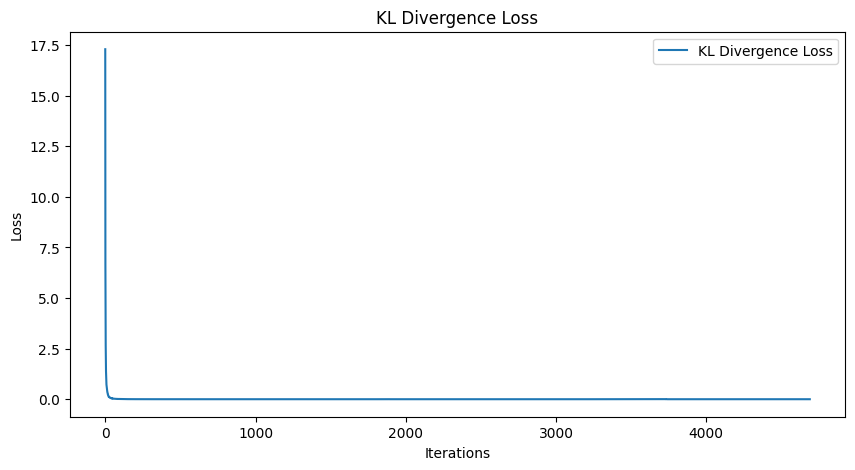
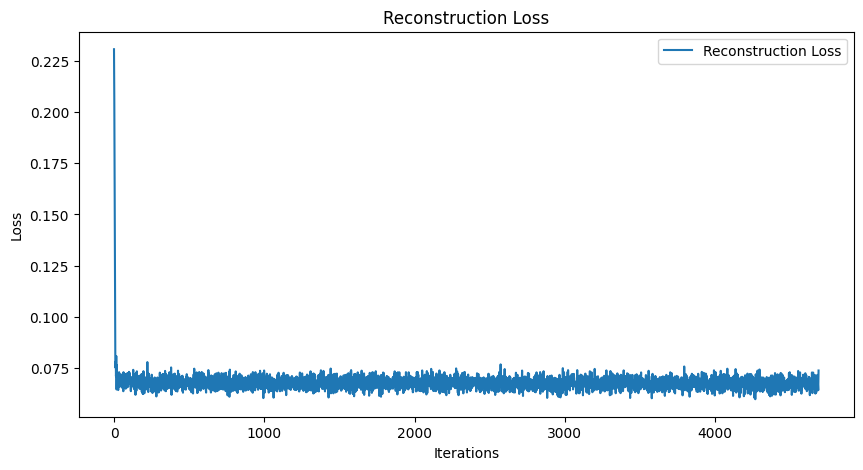
Digging deeper into the loss curves revealed another anomaly. Both the KL divergence and reconstruction loss exhibited a massive spike downward early in training. For the KL divergence, the loss dropped from around 17.5 in one batch to values oscillating between 0 and 1 in subsequent batches. Similarly, the reconstruction loss plummeted from 0.225 to 0.075 and then remained largely flat, with only minor fluctuations. This sudden and drastic drop was unexpected. Normally, we anticipate a gradual reduction in loss as the model learns over iterations, not a sharp fall followed by stagnation. Clearly, something unusual was happening, and it required further investigation.

Investigating the Issue: Architecture, Learning Rate, Batch Size, and Loss Function
To understand the root cause of the problem, I systematically experimented with various components of the model and training process. I started by revisiting the architecture of my VAE. Initially, I used a convolutional neural network (CNN) for both the encoder and decoder, which didn’t help. I switched to a fully connected (dense) architecture, hoping it might behave differently, but it didn’t help either.
Next, I experimented with different learning rates, without vail. Similarly, changing the batch size did not alter the output behavior of the model. Each time, the reconstructed images remained identical and blurred, and the loss curves continued to show the same unusual pattern.
At this point, I decided to compare my implementation to others by examining publicly available VAE projects on GitHub. While going through various implementations, I noticed a common pattern: many of them used Binary Cross-Entropy (BCE) as the reconstruction loss function, whereas I had been using Mean Squared Error (MSE). Curious, I modified my code to replace MSE with BCE for the reconstruction loss.
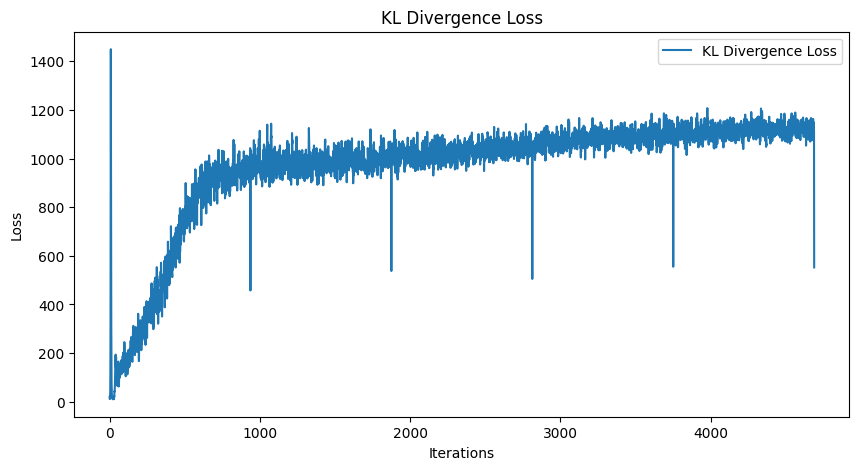
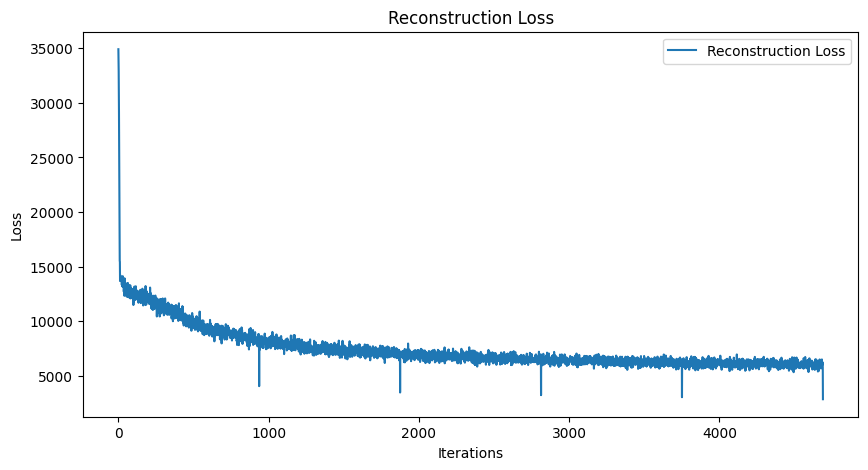
To my surprise, this simple change resolved the issue entirely. The reconstructions immediately became sharper and more varied, resembling the input images as expected. Moreover, the loss curves showed a gradual and stable decline (almost), indicating that the training process was now functioning as intended.
Here are the results after changing ONLY the loss function from MSE to BCE:
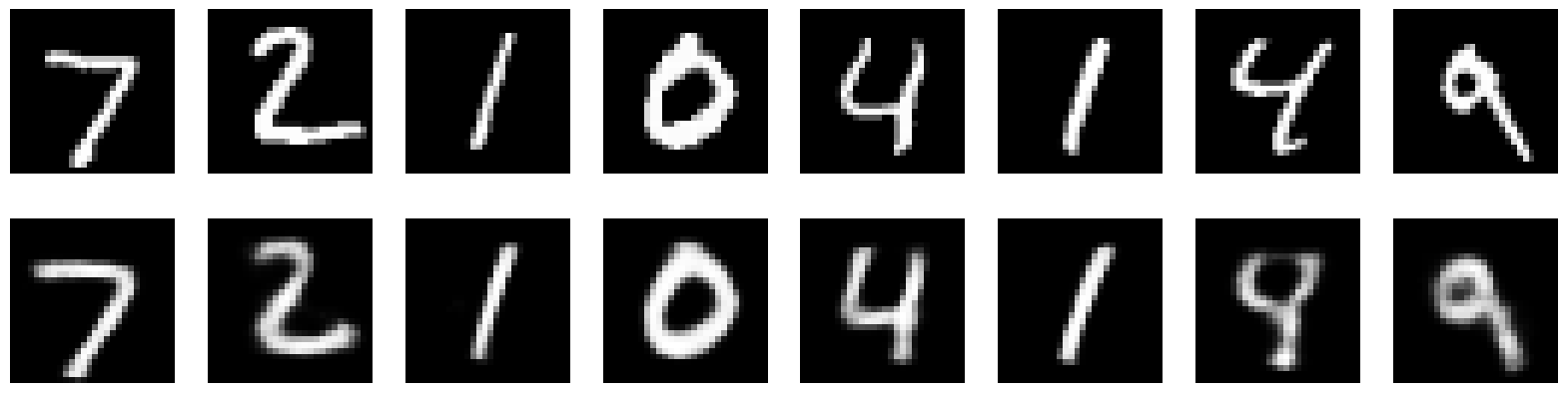
The only change I did in the code is the following:
def loss_function(x, x_hat, mean, log_var):
# Reconstruction loss
# Instead of MSE we use BCE
# recon_loss = nn.MSELoss()(x_hat, x)
recon_loss = nn.BCELoss(reduction='sum')(x_hat, x)
# KL divergence loss
kl_loss = -0.5 * torch.sum(1 + log_var - mean.pow(2) - log_var.exp())
return recon_loss + kl_loss, recon_loss, kl_loss
Why Does Changing the Loss Function from MSE to BCE Work Better?
After running into trouble with my VAE reconstructions, I turned to Reddit for insights and received a helpful explanation that clarified why switching from MSE to BCE improved the results.
The key difference between MSE and BCE is in how they treat the pixel values of the images. MSE assumes that the output follows a Gaussian distribution with a variance of 1, which is not an appropriate assumption for VAEs, as they are probabilistic models. This mismatch can cause MSE to behave poorly for image reconstruction tasks, especially in the context of generative models like VAEs. For regular AE model, it was fine, but when we are trying to do generative modeling, its better not to use MSE.
MSE is also highly sensitive to outliers, which is undesirable in image generation. Since MSE tries to minimize pixel-level differences, it tends to average out pixel values across the entire image. This often results in blurry reconstructions, as the model is essentially forced to produce an average value for each pixel. As a result, the fine-grained details in images are lost.
On the other hand, BCE works in a fundamentally different way. The BCE loss function is better suited for the range of pixel values in images, which typically range between 0 and 1. Unlike MSE, BCE doesn’t just minimize pixel-level differences; it forces the model to make predictions closer to the extremes of 0 and 1. This behavior encourages sharper, more defined outputs, even when the pixel values aren’t exactly correct. As a result, the decoder retains more of the original structure and detail.
In practice, switching to BCE addressed the issues I was facing with blurry and indistinguishable reconstructions. The model now generates images that more closely resemble the original MNIST digits.